

L’intégration d’event sourcing Kafka avec vos microservices : un guide étape par étape
En 2025, la nécessité d’optimiser l’architecture de développement logiciel s’impose à toutes les entreprises. La transformation numérique pousse les organisations à repenser leur façon de gérer les données. L’intégration d’Apache Kafka en tant que solution de messagerie distribuée et d’event sourcing est désormais au cœur des stratégies d’architecture microservices. Ce guide vous plongera dans un monde où l’asynchrone prend le pas sur le synchrone, où chaque événement devient une opportunité de modéliser des processus métiers avec une agilité inédite.
Comprendre les fondements de l’Event Sourcing et de Kafka
Avant de plonger dans l’intégration spécifique entre Kafka et l’Event Sourcing, il est essentiel d’explorer la signification de ces concepts. L’Event Sourcing est un modèle d’architecture où chaque état d’un système est stocké sous forme d’événements. Contrairement aux systèmes traditionnels où la dernière valeur d’une entité est simplement mise à jour, l’Event Sourcing conserve un journal de toutes les modifications apportées, permettant ainsi de reconstruire l’état à n’importe quel moment.
Apache Kafka, quant à lui, est une plateforme distribuée de streaming de données, qui permet le traitement en temps réel de flux de données. Conçu à l’origine par LinkedIn, il est devenu un projet open source largement adopté pour sa capacité à gérer de grandes quantités de données de façon robuste et scalable.
En combinant ces deux approches, les entreprises peuvent bénéficier d’une communication asynchrone entre microservices, facilitant ainsi la scalabilité et la découplage des systèmes. Pour mieux comprendre, considérons les éléments clés qui constituent cette intégration :
- Historique des événements : Les événements sont enregistrés de manière séquentielle, ce qui facilite leur audibilité et leur traçabilité.
- Scalabilité : Grâce à son architecture distribuée, Kafka peut s’étendre horizontalement, permettant de gérer un volume élevé d’événements.
- Performance : La capacité de Kafka à traiter des millions d’événements par seconde en fait un candidat idéal pour des applications nécessitant des réponses en temps réel.
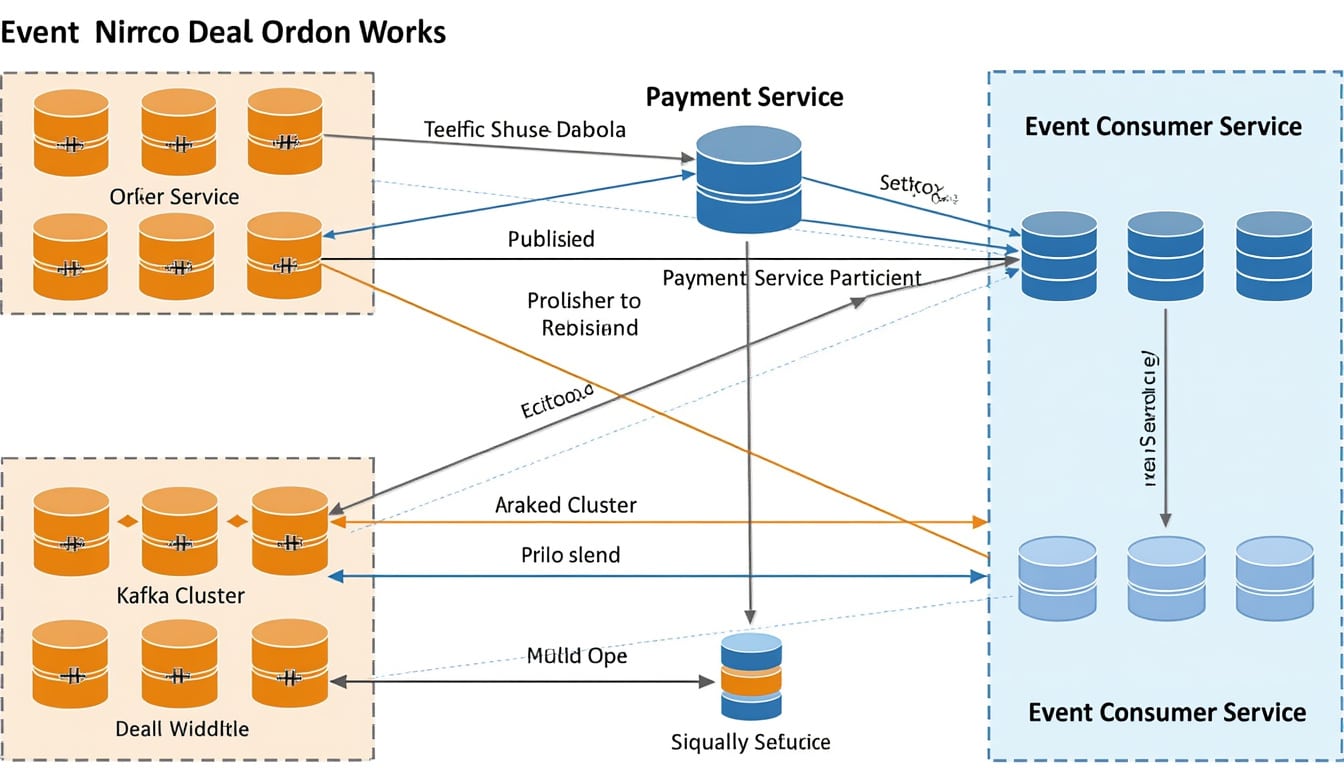
Les avantages de l’Event Sourcing avec Kafka
Adopter un modèle d’Event Sourcing couplé à Kafka confère plusieurs avantages significatifs aux organisations. D’abord, la possibilité de revivre l’historique des modifications permet une meilleure gestion des erreurs et une analyse approfondie des données. En cas de problème, il est possible de revenir à un état précédent en « rejouant » les événements.
Ensuite, cela ouvre la porte à des architectures plus flexibles. Les microservices ne dépendent plus d’un modèle de données unique, ce qui favorise leur autonomie et leur capacité à évoluer indépendamment. De plus, cela permet le développement de fonctionnalités comme le Log Compaction, qui garantit que seule la dernière version des données est conservée tout en maintenant l’historique complet des modifications.
Finalement, en intégrant des outils comme Kafka Connect, les données peuvent être facilement transférées entre des systèmes externes et votre architecture de microservices. Des connecteurs universels sont disponibles pour simplifier l’intégration entre divers systèmes de gestion de base de données, facilitant la synchronisation des données en temps réel.
Planifier l’intégration d’Event Sourcing avec Kafka
Une intégration réussie d’Event Sourcing avec Kafka nécessite une planification minutieuse. Cela commence par une évaluation claire des événements à capturer et de leur structure. Les événements doivent être définis de manière précise pour ne pas seulement représenter des états, mais aussi des actions métier significatives.
Voici quelques étapes clés à prendre en compte lors de la planification :
- Identification des événements : Quels événements doivent être surveillés ? Chaque interaction utilisateur, chaque mise à jour d’état, etc.
- Définition de la structure d’événements : Quel type de données chaque événement contient-il ? Une bonne pratique consiste à utiliser des formats de message standardisés comme JSON ou Avro.
- Configuration de Kafka : Définir les sujets de Kafka pour le stockage des événements. Cela implique de créer des topics spécifiques pour différents types d’événements.
- Création de producteurs et consommateurs : Développer des applications microservices qui pourront publier et consommer des événements sur les sujets Kafka définis.
Une planification rigoureuse permet non seulement d’anticiper les problèmes, mais aussi d’assurer que toute l’architecture s’intègre harmonieusement.
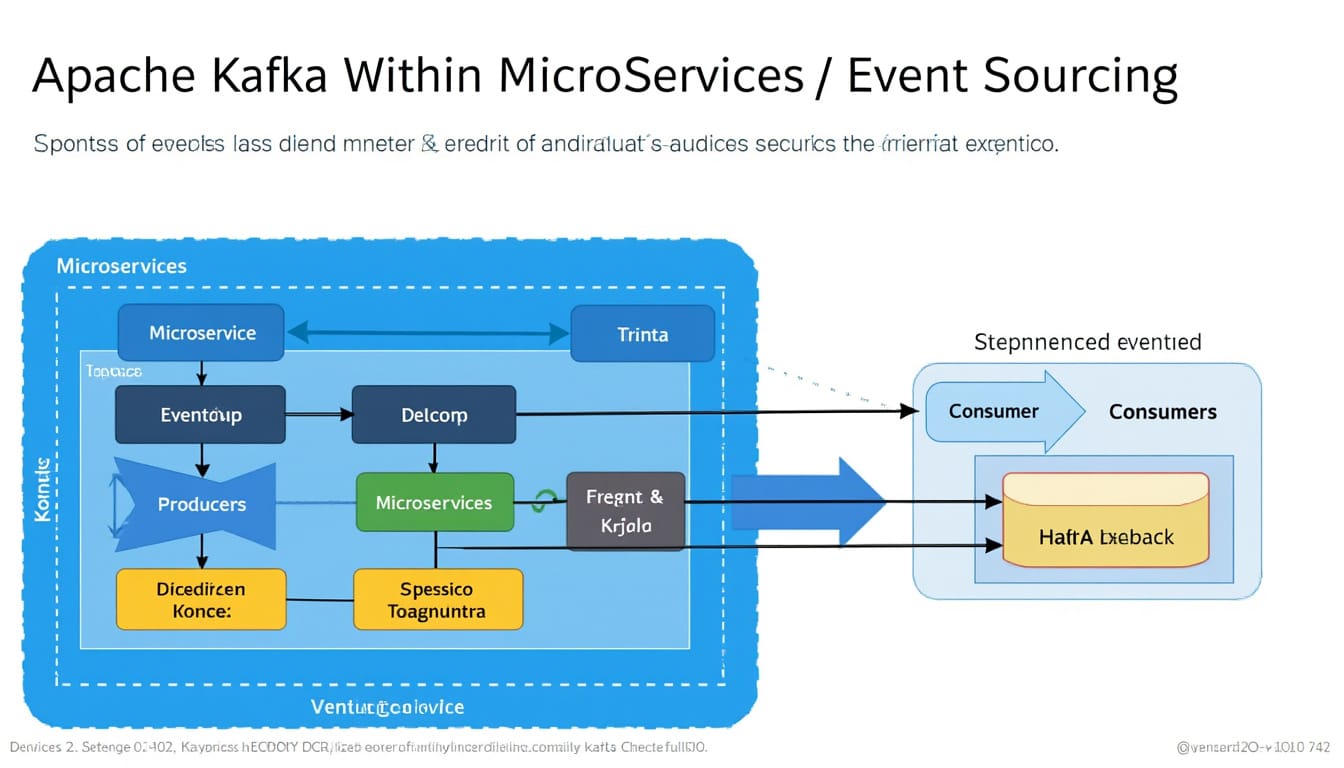
Établir la Communication entre Microservices avec Kafka
Une fois la planification réalisée, l’étape suivante consiste à établir la communication entre les microservices. Kafka agit comme un intermédiaire, permettant aux services de communiquer de manière asynchrone, ce qui peut considérablement améliorer les performances et réduire le risque de dépendances croisées.
Pour réussir cela, plusieurs considérations doivent être prises en compte :
- S’assurer de la résilience : Chaque microservice doit être capable de gérer les échecs de communication. Cela peut impliquer des systèmes de retry ou des motifs de circuit break.
- Consommer les événements : Mettre en place des consommateurs qui réagiront aux événements en fonction de leur logique métier. Chaque service doit savoir quoi faire lorsqu’il reçoit un événement particulier.
- Gestion des erreurs : Établir des mécanismes de suivi et d’alerte pour gérer les erreurs de consommation des événements, afin de garantir que les pertes de données ne se produisent pas.
Détails Techniques pour une Intégration Réussie
L’intégration technique de Kafka avec vos microservices en utilisant l’Event Sourcing nécessite une attention particulière sur plusieurs aspects. Cela inclut non seulement le choix de dieux outils, mais également leur configuration adéquate.
Parmi les outils essentiels, Kafka Streams est un véritable atout. Il permet de traiter les événements de manière fluide sans nécessiter d’infrastructure complexe. Les microservices peuvent utiliser Kafka Streams pour effectuer des opérations de lecture, d’écriture et de transformation des événements en temps réel.
Il est essentiel de créer des groupes de consommateurs, répondant ainsi à des microservices spécifiques qui peuvent consommer des événements de manière évolutive. Cela permet de créer une architecture qui soit non seulement performante, mais aussi facile à gérer.
| Élément | Fonction | Utilisation |
|---|---|---|
| Kafka Streams | Traitement des événements en temps réel | Effectuer des transformations et filtrer les données |
| Kafka Connect | Intégration avec des systèmes externes | Synchroniser les données en temps réel |
| Log Compaction | Conserver les dernières versions des données | Optimiser le stockage tout en conservant l’historique |
Gestion des Sécurités des Événements
Le stockage et le traitement des événements dans un environnement de microservices soulèvent des préoccupations majeures en matière de sécurité. Chaque événement enregistré doit être protégé pour garantir que des informations sensibles ne soient pas exposées.
Pour cela, il est recommandé de :
- Chiffrer les événements : Avant d’être envoyés dans Kafka, les événements sensibles doivent être chiffrés.
- Contrôler l’accès aux topics : Analyser qui a le droit de publier ou de consommer des événements.
- Auditer en continu : Enregistrer les accès et les modifications apportées aux événements à des fins de conformité.
Ces mesures garantiront que votre architecture de microservices, en utilisant Kafka pour l’Event Sourcing, réponde non seulement à des exigences techniques, mais également à des normes de sécurité strictes.
Développer et Tester avec une Intégration Continue
L’intégration d’Event Sourcing dans une architecture de microservices requiert de mettre en place un système d’intégration continue (CI) afin de garantir que chaque composant interagisse correctement. Les tests devraient être conçus pour valider non seulement la logique de chaque service, mais également leur capacité à traiter et à produire des événements conformément aux attentes.
Pour ce faire, il est nécessaire de :
- Créer des tests unitaires et d’intégration : Chaque microservice doit avoir des tests pour vérifier que les événements sont publiés et consommés comme prévu.
- Simuler des événements : Utiliser des mock servers pour simuler les flux de données entrants et sortants.
- Configurer des tests de charge : Évaluer la performance en soumettant des volumes élevés d’événements pour voir comment le système réagit à la pression.
Créer un pipeline CI efficace aide à simplifier le déploiement et à réduire les régressions qui pourraient surgir au fil du développement.
Les défis de l’Event Sourcing et des Solutions Pratiques
Bien que l’intégration d’Event Sourcing avec Kafka offre de nombreux avantages, plusieurs défis peuvent survenir. Il est crucial d’identifier ces obstacles pour mieux les surmonter.
Parmi les défis les plus courants, citons :
- Complexité d’architecture : La mise en place d’une architecture orientée événements peut être complexe, surtout pour les équipes qui ont l’habitude des architectures traditionnelles.
- Gestion des dépendances : Parfois, les services peuvent devenir trop dépendants des événements, entraînant des problèmes de couplage.
- Évolution des schémas : Les modifications dans les événements peuvent poser des problèmes lors de la consommation actuelle des données.
Afin de les surmonter, il peut être judicieux d’adopter des pratiques comme la versioning des événements, en gardant une trace de l’évolution des schémas au fil du temps. Cela permettra aux consommateurs d’évoluer sans interruption de service.
Exemples concrets d’implémentation réussie d’Event Sourcing avec Kafka
De nombreuses entreprises à travers le monde ont adopté l’intégration d’Event Sourcing avec Kafka pour transformer leurs architectures. Par exemple, une entreprise du secteur de l’e-commerce a mis en place un système basé sur Kafka pour gérer les interactions utilisateurs et les commandes. Grâce à cette décision, ils ont pu retracer chaque interaction, optimiser leurs délais de livraison et améliorer leur service client.
Un autre cas d’usage a été observé dans le secteur bancaire, où les institutions financières utilisent Kafka pour suivre toutes les transactions en temps réel. Cela leur permet non seulement de détecter rapidement les fraudes, mais aussi de fournir des rapports dynamiques et en temps réel sur les activités des comptes.
Exploiter les tendances futures de l’Event Sourcing avec Kafka
Avec l’évolution rapide de la technologie en 2025, il est probable que l’utilisation de l’Event Sourcing avec Kafka connaisse une adoption encore plus large. Les entreprises devront se concentrer sur la performance et la sécurité tout en cherchant à automatiser davantage leurs processus.
À mesure que les systèmes de bases de données deviennent de plus en plus sophistiqués, les technologies de streaming continueront à s’intégrer aux architectures modernes. Les tendances comme le Machine Learning pourraient également jouer un rôle central dans l’analyse des événements en temps réel.
Les défis persisteront, mais les opportunités offertes par l’architecture orientée événements sont trop importantes pour ne pas en tirer parti. En anticipant ces changements, les entreprises pourront rester compétitives et s’adapter aux exigences d’un monde en constante évolution.
Exemples synthétiques des défis et comment les surmonter
| Défi | Solution |
|---|---|
| Complexité d’architecture | Adapter les formations à l’architecture orientée événements |
| Gestion des dépendances | Utiliser des techniques de désaccouplement |
| Évolution des schémas | Versioning des événements pour maintenir la compatibilité |
Cette manière d’aborder le sujet permet de garder une vue d’ensemble sur les défis et les meilleures façons de naviguer à travers eux.
En somme, l’intégration d’Event Sourcing avec Kafka dans des architectures de microservices représente une véritable opportunité pour les entreprises visionnaires. Les bénéfices en termes d’agilité, de traçabilité des événements et de scalabilité n’ont jamais été aussi clairs.
Compétences requises pour maîtriser l’event sourcing avec Kafka
Pour mettre en œuvre avec succès une architecture basée sur Event Sourcing avec Kafka, certaines compétences spécifiques doivent être développées au sein des équipes de développement. En effet, la maîtrise des outils et concepts sous-jacents est indispensable pour garantir une intégration fluide.
Voici quelques compétences clés qui devraient être développées :
- Connaissance de Kafka : Comprendre son fonctionnement, ses configurations et ses limitations peut aider à maximiser son potentiel.
- Expertise en microservices : La conception de microservices de manière décentralisée et autonome est cruciale.
- Capacités en gestion des données : Les équipes doivent être familiarisées avec les modèles de données orientés événements et les meilleures pratiques pour leur gestion.
Ces compétences permettront non seulement de garantir une intégration réussie, mais aussi de maintenir la soutenabilité de l’architecture à long terme.
Évaluation continue et mise à jour des systèmes
Enfin, pour garantir que l’architecture basée sur l’Event Sourcing et Kafka reste performante face à l’évolution des besoins, il est également essentiel de prévoir des évaluations régulières et des mises à jour des systèmes. Cela inclut l’analyse périodique du système et des ajustements stratégiques basés sur des indicateurs de performance clés.
De plus, le retour d’expérience des équipes de développement et des utilisateurs finaux doit être pris en compte pour affiner et adapter les systèmes aux besoins changeants. Cela garantira non seulement une architecture réactive mais aussi une aventure alignée sur les valeurs initiales du projet.
À l’aube de cette vague de changement digital, le voyage d’intégration d’Event Sourcing avec Kafka dans vos microservices sera sans aucun doute enrichissant.
Quels que soient les défis que vous rencontrerez en cours de route, le cadre conceptuel que vous établissez aujourd’hui déterminera la résilience et la performance de votre architecture pour demain.
Questions Fréquemment Posées sur l’intégration d’Event Sourcing Kafka
Quelle est la différence entre Event Sourcing et la gestion traditionnelle des données ?
L’Event Sourcing stocke chaque changement d’état, permettant de revivre l’historique et de recréer un état antérieur, tandis que la gestion traditionnelle met simplement à jour la dernière valeur sans conserver l’historique.
Comment garantir la performance de Kafka dans une architecture de microservices ?
La performance peut être optimisée en configurant correctement les partitions des topics, en ajustant la taille des messages et en utilisant des groupes de consommateurs pour équilibrer la charge de travail.
Quelles sont les meilleures pratiques de sécurité pour l’Event Sourcing ?
Il est crucial de chiffrer les données sensibles, de contrôler l’accès aux topics et de maintenir un audit des accès et modifications d’événements pour garantir la sécurité.
Peut-on utiliser Kafka sans Event Sourcing ?
Oui, Kafka peut être utilisé pour de nombreux cas d’utilisation, notamment le streaming de données, la gestion de logs et les systèmes de notification, sans nécessairement utiliser Event Sourcing.
Quel est l’avenir de l’Event Sourcing et de Kafka dans les entreprises ?
L’avenir semble prometteur, avec une adoption croissante de l’Event Sourcing permettant des architectures plus souples et la capacité d’adaptation rapide aux exigences du marché.